Understanding Bloom Filter
I recently came across an fascinating blog post where the author explains how they crawled a quarter billion webpages in just 40 hours. One of the key techniques they used was a Bloom filter to efficiently track which webpages had already been crawled.
In this post author used Bloom Filter to capture if the web page is already crawled.
What is a bloom filter?
- Given an input bloom filter return true if the key might be present present else false. Bloom filter can return a false positive.
- In this particular use case where the author wanted to store all the web pages already crawled, he is using bloom filter to figure it check if crawler already visited the site.
- Advantage: You don’t need a lot of space to store data, you can have an in-memory datastore. The size of the datastore is known prior in the case of bloom filter
How does bloom filter works
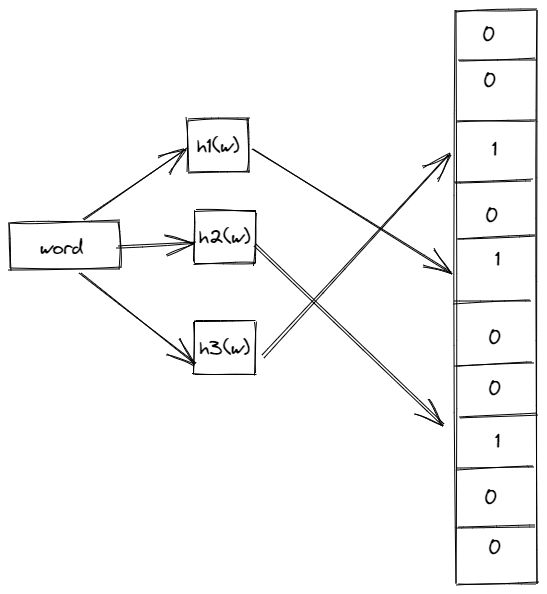
When inserting an element (e.g., a word or URL) into a Bloom filter:
The element is passed through multiple hash functions. Each hash function outputs a position in the filter’s bit array. The bits at these positions are set to 1.
Example:
- h1(“word”) % 10 = 2
- h2(“word”) % 10 = 4
- h3(“word”) % 10 = 7
We would set the 2nd, 4th, and 7th bits in the Bloom filter to 1.
Querying
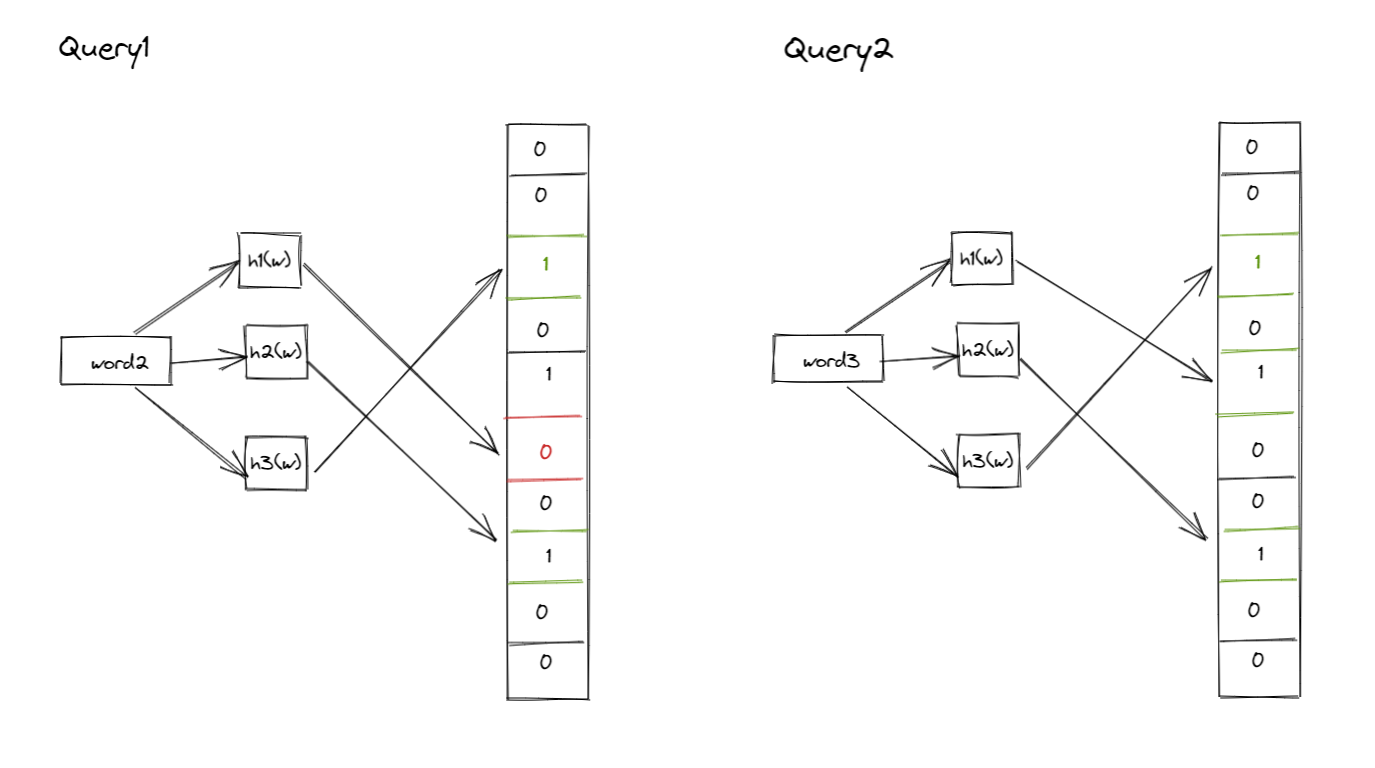
To check if an element exists in the set:
Pass the element through the same hash functions. Check if all the corresponding bits in the filter are set to 1. If all bits are 1, the element may exist in the set. If any bit is 0, the element definitely does not exist.
Limitations
- Possibility of false positives: The filter may indicate an element is in the set when it actually isn’t.
- Generally, there will be a second layer to check if the word exists if the bloom filter says exists.
- Elements can’t be removed from the standard Bloom filter.
- The size of the filter must be set in advance and can’t be resized without recreating the entire filter.
Time complexity
| Operation | Complexity |
|---|---|
| Insertion | O(k) |
| Find | O(k) |
k = Number of Hash function